

齿轮炼金术士
前言
最近,双足机器人占领了舆论头条,小米8月11日发布了自己的第一款人形机器人CyberOne,中文名叫铁大,而按照马斯克的计划,Tesla的人形机器人“Optimus(擎天柱)”原型机将在今年 9 月 30 日举行的 AI Day 上现身。作为仿生机器人的最高进化形态,人形机器人被认为具有广泛应用前景的机器人类型。当然,业内一直有机器人是否有必要做成人形的争论,我认为如果技术不再是壁垒,那就完全有必要,因为功能的集成化本来就是很大的优势,就像Dota中的极限法球要比同样属性的10个树枝贵很多。就像现在的手机一样,以前可能需要mp3,MP4,电子书,电脑,电话,钱包等等,现在一个手机搞定,我希望未来人形机器人也是一样。

当然,双足机器人的控制具有很高的技术难度,尤其是步态控制和平衡问题。因为机器人在移动过程中,外力方面只受到重力和地面的作用力,而重力和地面作用力不能直接控制,只能转而控制机器人关节的驱动力来控制机器人的行走,这样给双足机器人的控制增加了很大难度。
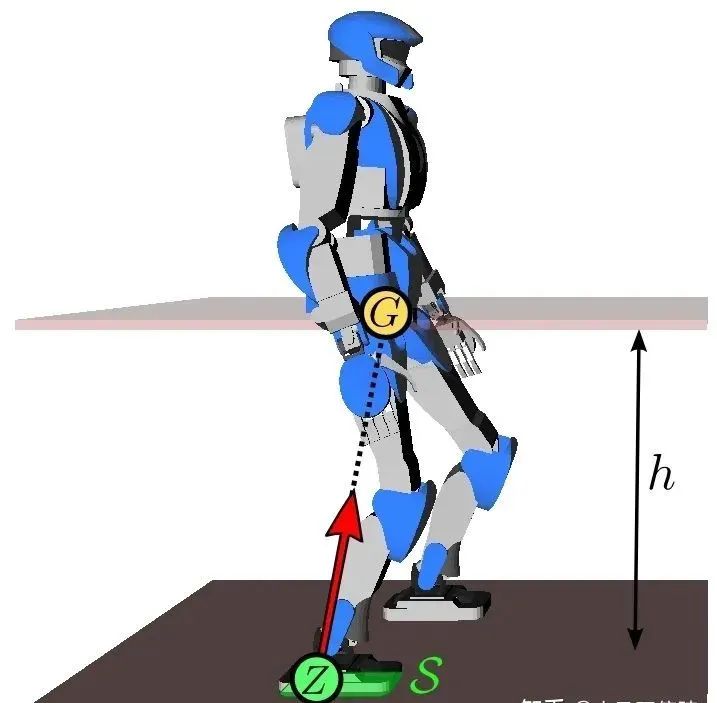
双足机器人依靠在重力和地面作用力行走。
目前对双足机器人步态的研究也经历了几十年,从最初如静步态行走、被动行走等方式发展到如今波士顿动力能灵活的跑酷、炫技。目前双足机器人的步态算法种类繁多,作为近几年刚入双足坑的人,想把一些具有代表性、且成功运用的双足控制算法整理一下,便于以后定位研究领域。本文建立在自己的整理上,肯定有疏漏,望指正、补充。
机器人的结构比较复杂,因此,在研究步态算法时,常常对机器人模型做简化处理,最初具有代表性的简化模型就是倒立摆(LIP)和弹簧负载倒立摆(SLIP)。但是这样的模型过于简单,一来没考虑腿的质量,二来将身体简化为质点,也没考虑身体姿态的影响,后来发展出来了centroidal dynamics,以及更复杂得 full-body dynamics,由此也衍生出了不同的控制方法。
1. 倒立摆+ZMP模型
倒立摆(LIP)算法以日本为代表,具有代表性的就是梶田秀司(Shuuji Kajita)所著的《人形机器人》一书,书中详细介绍了LIP+零力矩点(ZMP)在双足机器人步态上的应用[1]。该模型将机器人简化为一个倒立摆模型或小车-桌子模型,整体控制的目的是使实际的zmp位置与参考的zmp位置之间的误差尽可能小,这样机器人在运动过程中才能够稳定。所以需要根据期望的ZMP位置(期望的落脚点)计算出质心的运动情况和实际的ZMP位置,并且反馈跟踪ZMP位置。一般情况下,使用该控制方法要求机器人行走过程中质心高度是恒定的,因此只能屈膝步行。该控制方法最具代表性的机器人就是本田的Asimo机器人,他可以说当时最先进的机器人,至今也很难被超越,除此之外,还有优必选的Walker,还有德国宇航局的TORO等。
该算法之后又发展出了很多变形,如divergent component of motion(DCM)算法等,Kajita在2018年也提出了基于Spatially Quantized Dynamics(SQD)的算法,能够实现机器人更接近人类的直膝行走步态[2][3]。
2. 弹簧负载倒立摆模型(SLIP)
SLIP模型的控制算法首推Marc Raibert在1986写的《Leged Robot that Balance》一书[4],Raibert是前MIT教授,也是机器人公司波士顿动力的创始人,虽然波士顿动力的算法并未公开,但是有理由相信这本书中的理论占了重要的作用,并且书中提出的控制方法至今仍是很多机器人动态平衡的控制策略。在这本书中,Raibert将机器人简化成了弹簧倒立摆,并且将其控制浓缩成“三部独立控制法”(Three-Part Control),该方法摒弃了繁琐的理论公式,将弹跳机器人复杂的控制解耦为了三个部分:高度控制、前进速度控制、身体姿态控制。其中落脚点控制是“三部独立控制法”中的关键点。现在许多欠驱动的机器人速度控制仍使用的落脚点调节这种方法。“
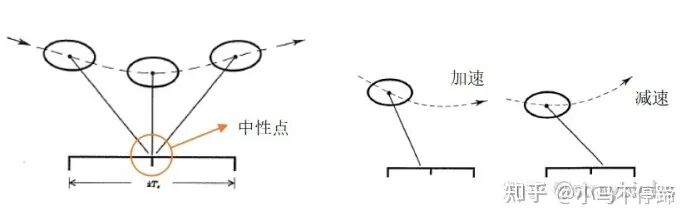
落脚点速度控制
之后对弹簧倒立摆模型的研究比较多,比较有代表性的是俄勒冈州立大学(OSU)的Jonathan W. Hurst,他是迅捷机器人公司(Agility Robotics)的CTO,著名得Cassie机器人就是出自他们公司,还有Cassie的变体Digit。他们早期在被动脚踝的ATRIAS上研究基于SLIP的动态步态,能够在不平地面上稳定性走。之后他们基于ATRIAS开发出来了著名的鸵鸟腿Cassie以及带上半身的Digit,Cassie出厂使用的算法就是基于弹簧倒立摆。现在他们转向主攻强化学习在双足机器人的应用,并且取得了很大的成果,Cassie已经能跑30分钟的越野,而Digit已经开始商业化。
3. Hybrid Zero Dynamics
密歇根大学的Jessy Grizzle主要采用的是Hybrid Zero Dynamics(HZD),该方法在full body dynamics上采用非线性控制理论,将机器人的行走分为单脚支撑阶段和双脚切换阶段,单脚支撑阶段可用Lagrange动力学描述,双脚切换可以看成一个刚体冲击(rigid impact),引起机器人速度突变。输出方程采用虚约束(Virtual constraint),即选择行走过程中的若干控制变量,将控制变量约束到目标值。采用输入输出线性化,将输出稳定在0。对该系统,用Trajectory Optimization产生最优步态,不同的步态构成Gait Library,行走时,控制器根据机器人状态从Gait Library取步态,然后关节跟踪,因此,该方法本质上还是位置控制,平衡方面采用的一般还是SLIP的foot-placement方法。他们这种方法在MABEL,ATRIAS,Cassie一系列机器人上成功使用。最近,他们提出基于角动量的速度和姿态进行调节方法,对不平地面具有更好的适应性[5]。

MABEL

另外加州理工大学Amber Lab 的Aaron Ames也主要采用HZD方法来控制机器人行走,甚至移植到了四足机器人上面。另外,他们团队的ayonga 开发了Trajectory Optimization的软件包frost-dev[6],大大简化了HZD理论的应用,这样机器人的在线控制部分本质上就成为了一个PID+速度姿态调节。
4. Whole Body Control(WBC)
另外值得提的是美国德克萨斯大学奥斯汀分校科克雷尔工程学院 Luis Sentis,他是Whole Body Control(WBC)方法的元老级人物,WBC已经成为DARPA挑战赛的通用控制方法。该方法主要思路是将机器人的多任务分优先级,采用零空间投影的方法将低优先级任务投影到高优先级任务零空间,以实现不同任务的层级。他采用该方法用于双足机器人控制,他们将控制器分为一个基于运动学的WBC模块(KinWBC)和基于动力学的WBC模块(DynWBC),KinWBC模块将机器人行走分为Double stance、Transition和Swing阶段,各个阶段有不同的任务层级,得到期望的关节角度、角速度和角加速度,然后传递给DynWBC模块,优化得到前馈力矩。他们用该方法在被动脚踝机器人Mercury上验证,具有很好的动态稳定性,并且能有效抵抗外界冲击。值得一提的是论文作者DONGHYUN KIM 在MIT时将WBC运用到了Mini Cheetah上,使得速度增大到3.7m/s,也是目前最火的四足开源控制算法。
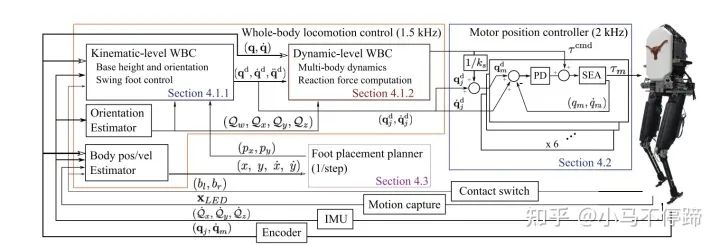
Mercury控制器架构
此外,,因为人形机器人具有冗余自由度,WBC方法最大的用处是在机器人整体操作上,可以产生很好的效果。
5. Model Predictive Control
模型预测控制(MPC)最初是用在自动驾驶领域,近几年越来越多地被用到足式机器人上,例如MIT开源的mini cheetah机器人的控制架构就是MPC,只是在MPC计算出足端力的基础上,又用WBC算法计算出关节力矩。另外,波士顿动力的atlas炫酷的跑酷、跳舞动作也是采用MPC实现的,根据团队leader Scott Kuindersma的介绍,他们算法框架分为offline和online两部分,首先根据机器人centroidal dynamics通过offline 优化出一系列Library of Template Behaviors(类似于HZD中的gait labrary),在online部分采用High-speed MPC来跟踪相应的Gait,并做动作的切换,产生作用力、落脚位置、时间等参数。

MPC是一种在线的优化控制算法,可以类似于mini cheetah那样,用于控制机器人的质心位置和姿态[7],也可跟其他双足机器人控制算法合用,比如用MPC去根据ZMP去规划质心的运动,采用MPC去跟踪HZD产生的Gaitlibrary中的步态及其切换,优必选研究院和清华大学赵明国老师的文章就有这方面研究[8]。
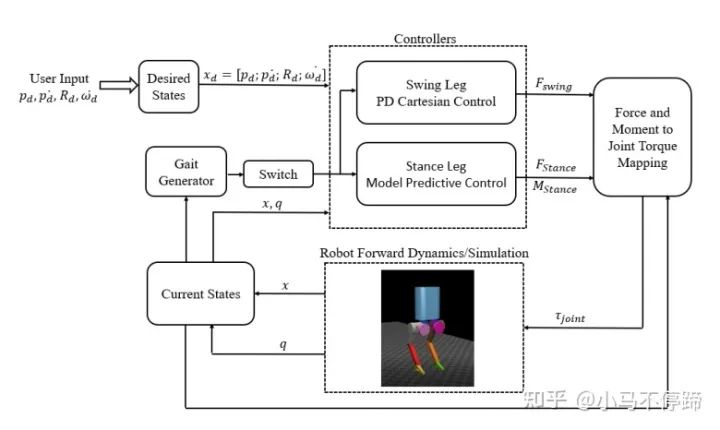
Force-and-moment-based Model Predictive Control for Achieving Highly DynamicLocomotion on Bipedal Robots

Fast Online Planning for Bipedal Locomotion via Centroidal ModelPredictive Gait Synthesis
6. Reinforcement Learning
随着机器学习的兴起,强化学习越来越多地被用来控制机器人,机器学习在处理高维度问题方面具天生的优势,而机器人一般维度比较高造成传统的控制方法一般都要做简化处理。强化学习类似于Monte Carlo方法,采用不断的抽样(试错)来得到最优的控制策略。现在常用的是深度强化学习,是将策略用神经网络来代替,得到机器人状态到动作的映射关系。强化学习常用OpenAI Gym环境,仿真环境一般用Mujoco,方法常用Deep Q-learning等,想在真实机器人训练比较难,因此现在都会用sim-to-real。Russ Tedrake早期主攻强化学习在双足机器人上的应用,他是MIT DARPA团队的领队,波士顿动力的Scott Kuindersma之前也是这个团队的。OSU 的Jonathan W. Hurst的团队现在也主攻在Cassie上运用强化学习方法,已经实现了Cassie跳跃、上楼梯等动作[9]。
以上是目前总结的主流的控制方法,其他一些不太好分类的相关知识也有很多,比如Russ Tedrake的Trajectory Optimization方法是机器人优化的核心方法,他们团队开发的Drake软件包也是机器人步态优化常用的工具。南方科技大学的张巍教授也对双足机器人有较多的研究,这里就不一一列举了,以后再做补充。