

齿轮啮合诗人
2025年,具身智能首次被写入《政府工作报告》,与生物制造、量子科技、6G等产业一起,成为国家重点培育的未来产业之一。
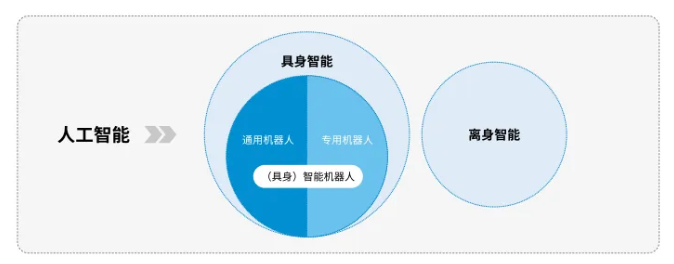
与之相对,离身智能的主要数据支撑是语言、文本、图像,主要在2D世界中运作,例如ChatGPT、DeepSeek,通义千问等,均为无实体载具的智能体;而具身智能(Embodied AI)则是人工智能与机器人学交叉的前沿领域,聚焦于3D真实物理世界,这一概念最早可追溯至1950年,计算机科学之父艾伦·图灵在其论文《计算机器与智能》中首次提出了具身智能的设想,其核心在于智能必须拥有一个物理实体,并通过该物理实体与周围环境进行实时互动、感知和学习,从而产生智能行为,并具备自适应调节能力。而机器人作为具身智能的核心物理实体,成为连接数字智能与物理AI的重要桥梁。
纵观机器人进化史,其中蕴含了人类对于将机械技术来复刻自然万物的独特理解。1996年,麻省理工学院的博士生大卫·巴雷特(David Barrett)创造了仿生机器人RoboTuna,用于研究鱼类如何在水中游泳;2011年,由Festo 的仿生学习网络创建的自主扑翼机SmartBird在汉诺威博览会上亮相,模拟了鸟类的自然振翅飞行。具身智能,正是将过往天马行空的创意与畅想,变成全面落地的现实生产力。
专用机器人与通用机器人是基于具身智能核心逻辑分化出的两大核心分支,二者的诞生、迭代与融合,本质是机器人对不同应用场景的适应性进化过程,共同构成了具身智能机器人从“功能特化”到“能力泛化”的演进历程。
专用机器人是机器人进化历程中场景适配的特化产物,其形态设计追随具体任务场景,以单一或某类垂直场景的效能最大化为核心目标。这类机器人无需拘泥于固定形态,而是根据作业需求演化出多元结构,如工业场景的关节型机械臂、物流场景的AGV搬运机器人、医疗场景的微创手术机器人等,其具身智能体现在“感知-动作”的精准闭环上一通过适配特定场景的传感器与执行机构,实现对单一任务的高效、稳定完成,是具身智能在垂直领域的深度落地形态。通用机器人则是机器人进化向复杂开放环境突破的泛化探索,以人形机器人为典型代表,设计根植于“身体结构适配人类社会”的进化逻辑,追求在多场景、非结构化环境下的通用交互能力。这类机器人以模仿人类身体形态与运动模式为基础,搭载多模态感知系统与全身协调控制算法,其出现标志着机器人从专用到泛化的突破,体现在“感知-决策-动作”的灵活联动上-一能够自主适应家庭、服务、救援等不同场景的任务需求,完成跨场景的复杂操作与社交交互,是具身智能向通用智能演进的核心载体。
从进化视角来看,专用机器人与通用机器人并非割裂对立的存在,而是在不同进化阶段相互支撑、协同演进:专用机器人的场景化技术积累,能够为通用机器人的泛化能力提供底层支撑;而通用机器人(人形机器人)的泛化探索方向,又可以在顶层设计上为专用机器人的功能拓展出新的进化路径。随着应用场景的深化,具身智能不仅需要感知和执行能力,还需要理解业务场景、业务逻辑和业务目标,才能真正融入企业的端到端业务流程、成为企业运营的智能资产,从场景端实现真正的「智能涌现」。

具身智能机器人名词定义
具身智能(Embodied Artificial Intelligence):具身智能是人工智能(AI)与其他学科交叉融合发展的新范式,从字面可理解为“具身+智能”,通过给Al赋予“身体”,使其能够与物理世界产生交互,并在交互中主动探索世界、认识世界、改变世界。
离身智能(Disembodied Intelligence):与“具身智能”相对,指智能可以脱离具体的物理载体(身体)而存在,主要依赖于抽象符号、逻辑推理和离线数据进行处理。传统AI和大多数大语言模型属于此类。
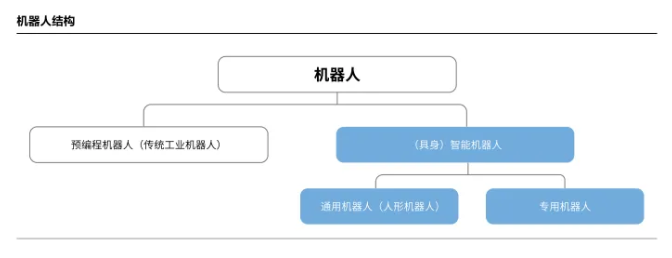
智能机器人(Intelligent Robot):智能机器人集机械学、电子学、计算机科学、控制论、人工智能等多学科知识于一身,具备自主决策、学习和适应能力,在工业、医疗、教育、家政、无人驾驶等领域的应用不断拓展,为人类生活带来便利和效率。涵盖“有物理形态”和“无物理形态”两类。
具身智能机器人(Embodied Artificial Intelligence Robot):具身智能机器人是智能机器人中“有物理形态”的高阶分支。具身智能机器人需要满足两个条件:一是具有物理的身体,二是能够与物理世界构成感知、思考、交互和行动的能力。与非具身智能机器人相比,具身智能机器人需要理解环境,适应变化的环境,准确和高效地完成任务,还需要更复杂的软件算法,其计算系统设计更具挑战。具身智能机器人的算法和任务是具身智能机器人的基础,理解具身智能机器人计算系统中的任务和软硬件系统,对于设计和理解具身智能机器人系统十分重要。
专用机器人(Specialized Robot):为特定、明确的任务而设计和优化的机器人。通常功能单一、形态多元、特定场景作业效率极高,但泛化能力弱。
通用机器人(General-Purpose Robot):以人形机器人为代表,是一种理想化的机器人概念,旨在像人类一样能够执行广泛、多样且未经预先编程的任务,并能适应新环境和新情况。
人形机器人(Humanoid Robot):人形机器人是具有躯干、头和四肢,外观和动作与人类相似的机器人。通常而言,人形机器人的狭义定义是拥有双臂手作业、双足行走的拟人化形态,同时拥有机器大脑、机器小脑的交互与学习进化能力,能够模仿人类适应多样化的任务场景的智能机器人。而人形机器人的广义定义则为拥有双臂手作业、足/轮行走等部分拟人化特征,采用大模型或具身智能等人工智能算法驱动,能够在专用或通用场景中完成指定的任务,并具有一定智能涌现或技能泛化能力的智能机器人。
生成式人工智能(Generative Artificial Intelligence):生成式人工智能是一种能够创建新数据样本的人工智能技术。这些样本可以是文本、图像,也可以是音频、视频等形式,它们既源于训练数据又超越了原始数据的范畴。
Agentic AI:Agentic Al是一类具备自主性(Autonomy)、目标导向(Goal-Directed)和交互性(Interactivity)的人工智能系统,能够像人类代理一样在复杂、多变的环境中感知信息、进行推理、制定决策并执行任务,从而实现目标驱动的智能化行为。
物理AI:物理AI是指使用运动技能理解现实世界并与之进行交互的模型,它们通常封装在机器人或自动驾驶汽车等自主机器中。
VLA(Vision-Language-Action):一种多模态Al模型,它直接整合视觉感知、语言理解和动作控制,是迈向通用机器人的关键技术。VLA模型接收视觉和语言指令,直接输出机器人动作。VLA模型的核心是打破传统AI中“视觉(仅识别)、语言(仅理解)、动作(仅执行)”的孤立状态,通过多模态融合实现“感知-理解-动作”的端到端协同。
世界模型(WorldModel):世界模型是理解现实世界动态的神经网络,包括物理和空间特性。它们可以使用输入数据,包括文本、图像、视频和运动,来生成模拟真实物理环境的视频。物理人工智能开发人员使用世界模型来生成定制的合成数据或下游人工智能模型,用于训练机器人和自动驾驶汽车。
Sim2Real (Simulation to Reality,即仿真到现实):是一种旨在将仿真环境中训练的人工智能模型或系统有效迁移并应用于现实物理世界的技术,主要应用于机器人、自动驾驶及具身智能等领域。现实世界的数据采集往往面临成本高昂、安全风险大以及效率低下等瓶颈,而仿真环境则能提供一个廉价、安全且可加速采样的“虚拟训练场”。然而,仿真环境与真实世界之间不可避免地存在“域差距”(DomainGap),例如传感器噪声、物理参数(如摩擦系数)、光照条件以及物体纹理等方面的差异。