

精工解码
当家庭服务机器人面对“把马克杯放进抽屉并关紧”“将西兰花放入冰箱保鲜层”这类多样化任务时,我们总希望它能像人类一样“举一反三”。
传统多任务模型为了兼顾通用性,往往陷入“样样通却样样松”的负迁移困境;现有检索式学习要么困于领域特定编码器的局限性,要么受限于全轨迹检索的粗粒度,无法挖掘不同任务间共享的底层动作规律。
就在这样的技术困局中,华盛顿大学与博世人工智能中心联合提出的STRAP(Sub-sequence Trajectory Retrieval for Augmented Policy Learning)框架横空出世,以“子轨迹检索”为核心创新点,构建了一套从数据利用到政策训练的完整解决方案。
项目链接:https://weirdlabuw.github.io/strap/static/documents/strap_2025.pdf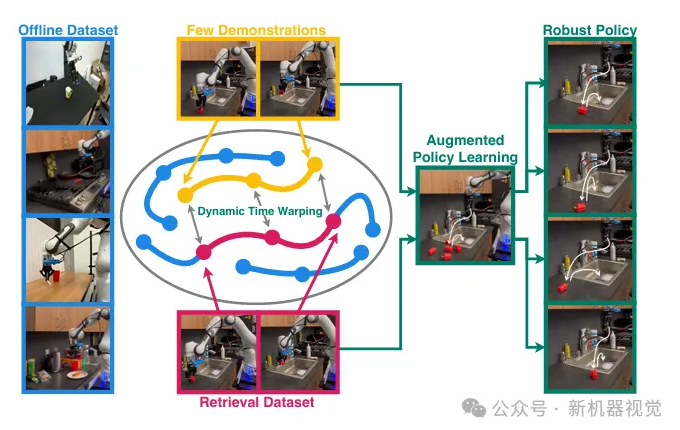
一、STRAP有什么用?
在STRAP出现之前,机器人少样本模仿学习始终被三重枷锁牢牢束缚,这些痛点也直接催生了STRAP方法体系的设计逻辑。
1、多任务学习的“负迁移陷阱”
多任务策略训练的初衷本是“集百家之长”——通过整合大量不同任务的数据,让模型习得通用技能以适应新场景。但现实往往事与愿违:不同任务的语义逻辑存在天然冲突,模型为了覆盖更多任务,不得不牺牲单任务的优化精度,最终陷入“平均主义陷阱”。
比如训练一个同时包含“拾取易碎花瓶”和“搬运沉重铁块”的模型时,前者需要轻柔缓慢的动作,后者需要果断有力的发力,模型很难同时兼顾两种动作的核心特征,导致在单独执行任一任务时都表现拉胯。
2、传统检索方法的“粒度困境”
检索式学习本是少样本场景的“救星”——利用少量目标任务数据,从大规模离线数据集中检索相关样本辅助训练。
但现有方法存在两大致命缺陷:
一是“特征鲁棒性不足”,依赖在特定数据集上训练的领域特定编码器,一旦环境光照、物体纹理发生变化,特征提取就会“失效”;
二是“检索粒度不合理”,要么检索单个状态-动作对,丢失了动作的时序动态信息;要么检索完整轨迹,而完整轨迹中往往包含大量与目标任务无关的片段,同时无法捕捉不同任务间共享的局部行为。
举个具体的例子:当目标任务是“将碗放入橱柜抽屉并关闭”时,现有全轨迹检索方法可能因为找不到“完全一致的完整轨迹”而束手无策,却忽略了“拾取碗”“推动抽屉关闭”这些核心子动作,在“将杯子放在抽屉上”“打开顶柜并关闭底柜”等其他任务中其实普遍存在。
这种“捡了芝麻丢西瓜”的检索方式,让大量有价值的跨任务数据被浪费,直接限制了模型的泛化能力。
3、视觉差异与数据效率的“矛盾死结”
现实世界的机器人操作场景,天生具有“多样性”特质:同样是“拾取苹果”,在厨房的暖光环境下、书房的冷光环境下,甚至苹果表面是否带水珠,都会导致视觉观测的巨大差异。现有方法大多依赖“场景专属”的特征提取器,环境一变,特征表示的鲁棒性就急剧下降,检索和训练效果自然大打折扣。
同时,机器人学习对“数据效率”的要求极高。在家庭服务场景中,不可能为每个新任务收集几十上百次专家演示——不仅耗时耗力,还可能因场景限制(如操作易碎品、危险品)无法重复收集。
正是这三重枷锁的叠加,让研究团队意识到:必须跳出“全轨迹检索”和“多任务蛮力训练”的固有思维,从“子轨迹”这一更精细的粒度切入,构建一套全新的方法体系——STRAP由此诞生。
二、STRAP的核心方法
如果把STRAP比作一台精密运转的“智能检索-训练引擎”,那么子轨迹分割、视觉特征编码、子序列动态时间规整检索(S-DTW)、语言条件政策训练这四大模块,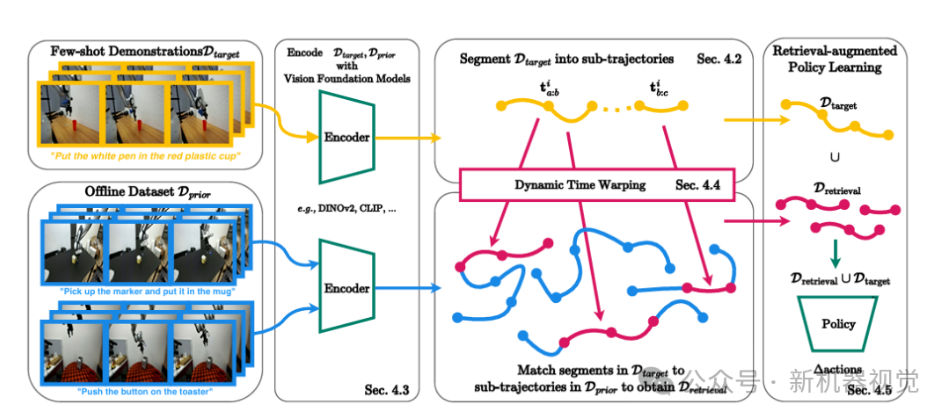
1、子轨迹分割:
其核心逻辑很简单:机器人执行原子动作时,末端执行器的速度会呈现“启动-稳定-停止”的规律;而在两个原子动作之间的过渡阶段,末端执行器的速度会趋近于零。基于这一特性,STRAP设定了一个速度阈值,当机器人末端执行器的速度绝对值持续低于该阈值时,就判定为“动作过渡点”,以此为界分割子轨迹。
比如在“拾取碗-放入抽屉-关闭抽屉”的完整轨迹中,机器人拾取碗后会有短暂的停顿(速度趋近于零),这个停顿点就会被识别为“拾取碗”和“移动碗到抽屉”两个子轨迹的分界点;而在将碗放入抽屉后,又会有一个停顿点,分割出“移动碗到抽屉”和“关闭抽屉”两个子轨迹。为了避免分割出过短的“无效片段”,STRAP还会对长度小于20个时间步的子轨迹进行合并,确保每个子轨迹都能完整反映一个原子动作的动态过程。
这种自动分割方法的优势显而易见:
一是完全脱离对外部标注的依赖,适配任意任务场景;
二是分割精度高,能精准捕捉原子动作的边界;
三是效率极高,可实时处理机器人的轨迹数据。正是这一模块,为STRAP后续的精准检索打下了“零件级”的基础。
2、视觉特征编码:
子轨迹分割完成后,下一步就是提取特征——这是检索的“核心依据”。传统方法的痛点在于,特征提取器是“场景专属”的,换个环境就“失灵”。STRAP的解决方案是:直接采用预训练的视觉基础模型作为特征提取器,利用其在海量数据上习得的“通用视觉认知能力”,抵御场景变化的干扰。
具体的编码过程非常简洁:STRAP将机器人的相机观测(包括手部特写相机和全局场景相机的图像)输入视觉基础模型,直接输出768维的特征向量。与传统方法不同的是,STRAP不会对一个子轨迹中的连续观测特征进行“时序平均”,而是完整保留每个时间步的特征向量——因为原子动作的动态性恰恰体现在“特征随时间的变化规律”中,平均化会丢失关键的时序信息。
为了验证这种编码方式的鲁棒性,研究团队做了一组对比实验:分别用DINOv2、CLIP和传统的领域特定编码器提取特征,在不同光照、不同物体姿态的场景下进行检索。
更重要的是,这种编码方式完全“开箱即用”——不需要在机器人数据集上进行任何微调,极大降低了部署门槛。对于机器人开发者而言,只需将相机图像输入预训练模型,就能得到鲁棒的特征向量,无需再花费大量精力训练专属编码器。
3、S-DTW检索:
有了“零件”(子轨迹)和“语言”(特征向量),接下来就是最关键的一步:如何从大规模离线数据集中,精准找到与目标子轨迹最相似的子轨迹?这就需要解决两个核心问题:一是目标子轨迹与候选子轨迹的“长度可能不同”;二是两者的“时序节奏可能存在差异”(比如一个动作快,一个动作慢)。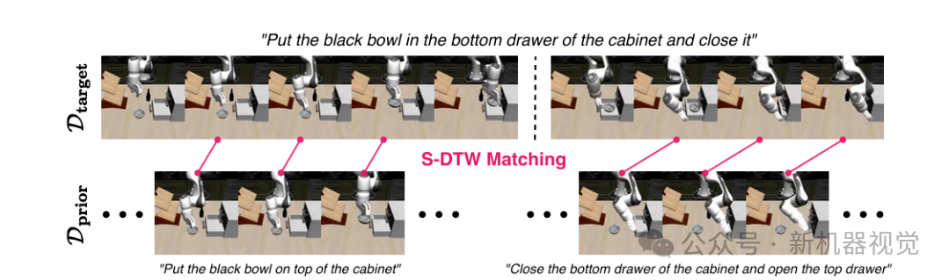
S-DTW的运作过程可以分为“三步走”,我们用一个具体例子来理解:假设目标子轨迹是“拾取碗”(包含50个时间步,特征序列为Q),候选轨迹是“拾取杯子-移动到桌面-关闭抽屉”(包含200个时间步,特征序列为C),我们需要从C中找到与Q最相似的子片段。
第一步,构建“距离矩阵”。 计算Q中每个时间步的特征向量与C中每个时间步的特征向量之间的L2距离(欧氏距离),得到一个50×200的矩阵。矩阵中的每个元素(i,j)代表Q的第i个时间步与C的第j个时间步的特征相似度——数值越小,相似度越高。
第二步,计算“累积距离矩阵”。通过动态规划的方式,从矩阵的左上角(Q[0], C[0])开始,逐步计算每个位置(i,j)的累积距离。累积距离的计算公式为:当前距离(i,j)加上“前一步的最小累积距离”(可以是(i-1,j)、(i,j-1)或(i-1,j-1)中的最小值)。这一步的核心作用是“允许时序错位”——比如Q的第10个时间步,可以与C的第12个时间步对齐,只要整体的累积距离最小。
第三步,回溯找到“最优匹配子片段”。遍历累积距离矩阵的最后一行(对应Q的最后一个时间步),找到累积距离最小的位置(50,j);然后从该位置反向回溯,找到一条累积距离最小的路径,这条路径对应的C中的子片段,就是与Q最相似的子轨迹。
与传统检索方法相比,S-DTW的优势堪称“降维打击”:一是能处理“长度不一致”的序列,比如50步的目标子轨迹可以匹配70步的候选子片段;二是能实现“局部匹配”,从完整轨迹中精准提取有用的子动作;三是能保证“时序一致性”,避免单个状态匹配带来的动态信息丢失。
在实际检索时,STRAP会为每个目标子轨迹检索K个最相似的子轨迹(K值可根据任务调整),然后将这些检索到的子轨迹组合成“增强训练集”。
4、语言条件政策训练:
这个政策模型的结构设计非常精巧,分为“输入层-融合层-预测层”三个部分。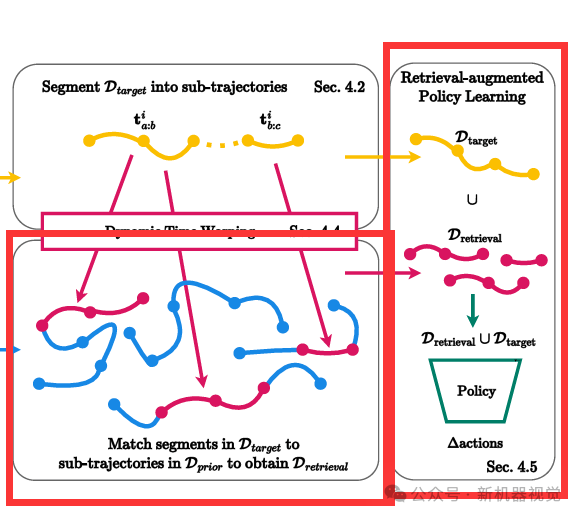
输入层包含两个分支:
一是“历史观测分支”,将过去h个时间步的视觉特征输入时序编码器(采用Transformer的编码器结构),捕捉动作的动态规律;
二是“语言指令分支”,将目标任务的自然语言指令(如“将碗放入橱柜抽屉并关闭”)输入文本编码器,转化为语义特征向量。
融合层通过注意力机制,将历史观测特征与语言语义特征进行深度融合——模型会自动关注与语言指令相关的视觉特征,比如当指令是“放入橱柜”时,模型会重点关注“橱柜”的视觉特征,而非背景中的“餐桌”。预测层则采用高斯混合模型,根据融合后的特征预测未来多个时间步的动作序列(包括位置、姿态、抓取力等连续动作参数)。
在训练过程中,模型的损失函数由两部分构成:
一是“多步动作对数似然损失”,确保模型预测的动作序列与真实动作序列尽可能一致;
二是“L2正则化项”,防止模型因过度拟合检索数据而丢失目标任务的核心特征。
训练数据采用“目标任务数据+检索增强数据”的混合批次,其中目标任务数据占比10%-20%,确保模型不会偏离目标任务的核心要求。
三、总结与展望:
STRAP的横空出世,不仅解决了机器人少样本模仿学习的三大核心痛点,更开启了一种全新的学习范式——将大规模离线数据集视为“原子动作知识库”,通过子轨迹检索按需提取有用信息,实现“少量示范+精准检索+高效训练”的闭环。其核心方法体系的创新点,可以概括为三点:
一是“粒度革新”,将检索从“完整轨迹”下沉到“子轨迹”,挖掘了跨任务共享的原子动作,从根本上解决了负迁移问题;
二是“特征鲁棒化”,借助预训练视觉基础模型,摆脱了对领域特定编码器的依赖,提升了场景适应性;
三是“语义融合”,通过语言条件政策模型,过滤了检索数据中的噪声,确保了训练的有效性。
当然,STRAP并非完美无缺。在子轨迹分割方面,目前的速度阈值法对“连续无停顿动作”(如搅拌咖啡)的分割精度仍有提升空间;在检索效率方面,面对百万级轨迹数据集时,S-DTW的计算成本仍需优化。未来,研究团队可结合视觉基础模型的语义信息,实现“语义级子轨迹分割”;同时引入近似最近邻索引算法,进一步提升大规模数据集的检索速度。