
节点卫士
0.这篇文章干了啥?
这篇文章提出了一种结合视觉和触觉传感器数据来估计机器人手中物体 6D 姿态的方法。现有 6D 姿态估计方法多依赖视觉数据,而机器人抓握物体时的严重遮挡会影响仅依靠视觉数据的方法,许多机器人指尖配备的触觉传感器可补充视觉数据。文章主要挑战包括触觉传感器数据缺乏标准表示、异构源(视觉和触觉)传感器数据融合以及需要大量训练数据集。为解决这些问题,首先提出用点云表示与触觉传感器接触的物体表面;其次,提出基于像素级密集融合的网络架构来融合视觉和触觉数据以估计物体的 6D 姿态;第三,扩展 NVIDIA 的深度学习数据集合成器,为 YCB 对象和模型集中的 11 个对象生成合成的逼真视觉数据和相应的触觉点云。实验结果表明,使用触觉数据结合视觉数据可提高手中物体 6D 姿态估计的准确性,且在真实物理机器人上的实验显示,在合成数据集上训练的网络能推广到不同物理设置。此外,文章还进行了消融研究和与现有技术的比较,指出该方法的局限性,并提出了未来工作的方向,如使用长短期记忆网络利用时间连贯性过滤错误估计、利用抓手几何形状和手指位置过滤不合理姿态估计、扩展数据集以包含不对称对象以及测试方法对不同环境遮挡水平的鲁棒性。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:VisuoTactile 6D Pose Estimation of an In-Hand Object using Vision and Tactile Sensor Data
作者:Snehal Dikhale, Karankumar Patel, Daksh Dhingra, Itoshi Naramura, Akinobu Hayashi, Soshi Iba, Nawid Jamali
作者机构:Honda Research Institute USA, Inc.;Honda R&D Co., Ltd. Innovative Research Excellence, Saitama, Japan;Department of Mechanical Engineering, University of Washington, Seattle, USA
论文链接:https://arxiv.org/pdf/2601.01675
2. 摘要
摘要
物体的 6D 位姿信息有助于手中物体的操作。现有的 6D 位姿估计方法使用视觉数据。由于机器人抓手造成的严重遮挡,手中物体的 6D 位姿估计具有挑战性,这会对仅依赖视觉数据的方法产生不利影响。许多机器人的指尖配备了触觉传感器,可用于补充视觉数据。在本文中,我们提出了一种方法,该方法同时使用触觉和视觉数据来估计机器人手中抓取物体的位姿。这项研究的主要挑战包括:
触觉传感器数据缺乏标准表示;
来自异构源(视觉和触觉)的传感器数据融合;
需要大量的训练数据集。
为了解决这些挑战,首先,我们建议使用点云来表示与触觉传感器接触的物体表面。其次,我们提出了一种基于像素级密集融合的网络架构,用于融合视觉和触觉数据,以估计物体的 6D 位姿。第三,我们扩展了英伟达的深度学习数据集合成器,以在虚幻引擎 4 中为 YCB 物体和模型集中的 11 个物体生成合成的逼真视觉数据以及相应的触觉点云。我们展示了模拟实验的结果,表明除视觉数据外使用触觉数据可提高手中物体的 6D 位姿估计精度。我们还展示了在真实物理机器人上部署网络的定性实验结果,表明在合成数据上训练的网络能够成功迁移到真实系统中。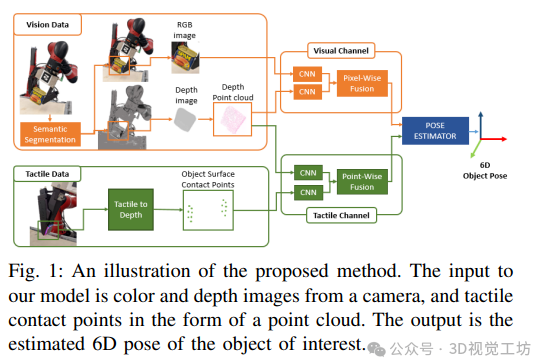
3. 效果展示
图10:第V-B节所述实验部署的可视化结果。绿色点云为Tactile-Channel输出,蓝色点云为基线方法输出。
Setup-I:左侧为主相机视角;右侧白色点云为运动捕捉系统提供的真位姿。
Setup-II:无运动捕捉系统,仅展示两方法对比。
图11:在第V-B节所述机器人Setup-I上,不同遮挡程度下的位姿估计结果。白色点云为运动捕捉系统提供的真值,绿色点云为我们网络的估计,蓝色点云为基线方法的估计。
4. 主要贡献
文章的主要贡献如下:
一种触觉传感器不变表示法,用于捕捉手指与物体的接触表面。
一种网络架构,用于融合视觉和触觉数据,以估计在严重遮挡情况下手中物体的 6D 姿态。推荐课程:机械臂6D位姿估计抓取从入门到精通。
一种生成适用于手中物体 6D 姿态估计的合成视觉触觉数据集的方法。
5. 基本原理是啥?
融合视觉与触觉数据的 6D 姿态估计方法现有的 6D 姿态估计方法多依赖视觉数据,而手持物体的 6D 姿态估计因机器人抓手造成的严重遮挡而具有挑战性。本文提出一种融合视觉和触觉数据来估计机器人手中物体 6D 姿态的方法,以解决现有方法仅依赖视觉数据的不足。
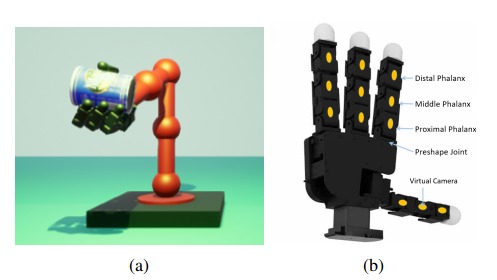
基于点云的触觉数据表示为解决触觉传感器数据缺乏标准表示的问题,提出用点云表示与触觉传感器接触的物体表面。通过前向运动学获取与物体接触的每个触觉单元的 3D 位置,这种表示使网络对触觉传感器类型和抓手类型具有不变性。
像素级密集融合的网络架构
视觉通道:对相机的彩色图像进行语义对象分割,将深度图像根据分割结果转换为相机坐标系下的 3D 点云。彩色图像经裁剪后输入卷积神经网络得到颜色特征嵌入,颜色嵌入和深度嵌入通过像素级密集融合。
触觉通道:输入为相机深度图像的点云和触觉传感器的物体表面点云,将所有手指的触觉数据作为单个 3D 点云输入网络,经过两级卷积神经网络生成触觉嵌入,触觉嵌入和深度嵌入通过逐点密集融合。
全局特征:融合颜色、深度和触觉嵌入,经过卷积神经网络和平均池化层生成全局特征,为网络提供全局上下文。
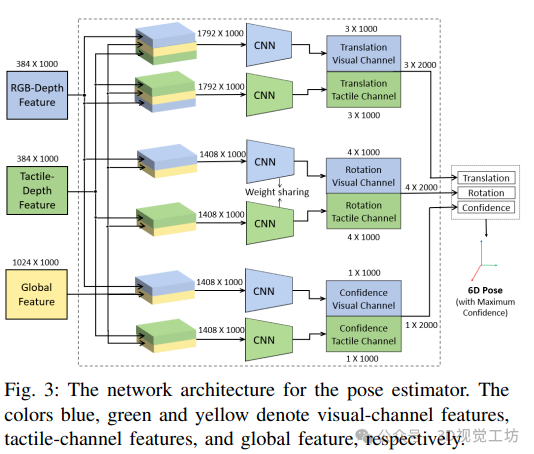
姿态估计器将视觉通道的 RGB - 深度特征、触觉通道的触觉 - 深度特征和全局特征输入姿态估计器。网络为视觉通道和触觉通道的每个特征估计平移向量、旋转向量和置信度水平。估计平移向量时,将相关特征分别输入视觉通道和触觉通道的卷积神经网络;估计旋转向量时,采用孪生网络架构,两个网络共享权重;置信度水平通过将相关特征输入相应通道的卷积神经网络进行估计。
合成视觉触觉数据集生成方法扩展 NVIDIA 的深度学习数据集合成器(NDDS),利用虚幻引擎 4 生成具有逼真照片效果的模拟数据,包括彩色和深度数据以及触觉点云,同时生成 11 个 YCB 对象的真实 6D 姿态。数据集包含每个对象 20000 个示例,并采用域随机化技术增加数据的多样性。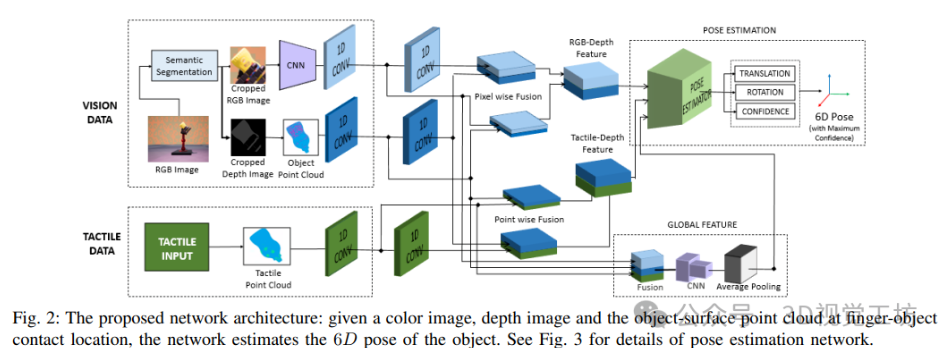
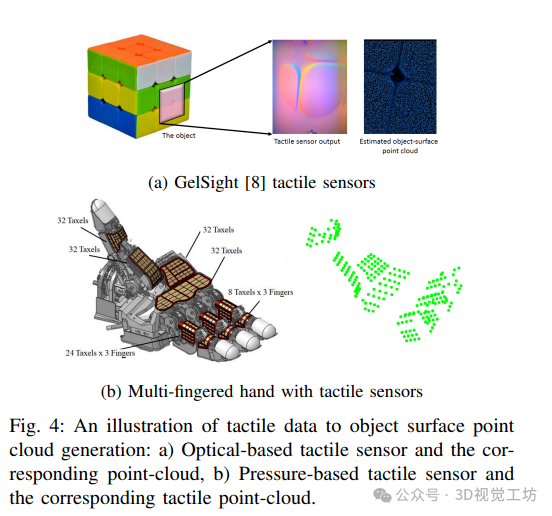
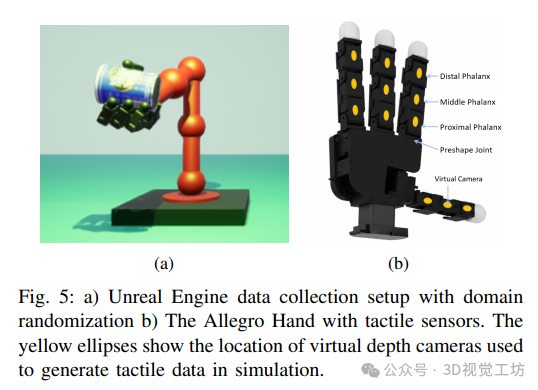
6. 实验结果
文章通过模拟和实际硬件实验,验证了所提方法在估计手中物体 6D 位姿方面的有效性和优势,具体实验结果如下:
定量评估
位置和角度指标性能:除饼干盒外,网络在所有物体上的表现均显著优于仅使用视觉数据的基线方法。例如,可调节扳手的位置误差从基线的 1.14cm 降至 0.36cm;在角度估计方面,可调节扳手和剪刀也有显著改善,但整体角度估计的提升幅度不如位置估计明显。
遮挡水平对性能的影响:随着遮挡程度增加,基线网络的性能显著下降,而所提网络在重度遮挡下仍能保持较好性能。在重度遮挡时,所提网络的平均位置误差为 0.4 ± 0.003cm,约为基线(0.78 ± 0.008cm)的一半;角度误差降低了 2.3 度。
触觉点数对性能的影响:减少触觉接触点数量会增加位置和角度误差,但即使触觉接触点数量减少,使用触觉数据的网络仍优于仅使用视觉数据的基线网络。
定性评估
位置和角度指标性能:在实际硬件部署中,所提网络的逐帧输出比基线网络更稳定,能够利用触觉信息获得更准确的物体 6D 位姿估计。
遮挡水平对性能的影响:通过在实际硬件上逐渐增加遮挡程度的实验表明,所提网络在处理高遮挡情况时优于基线网络。
消融研究
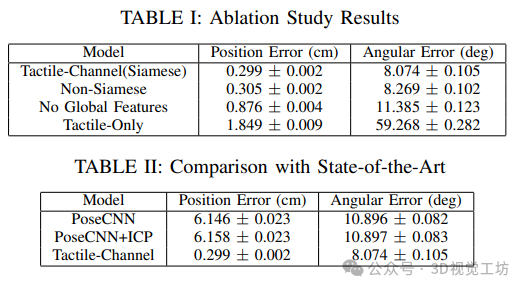
暹罗网络:使用暹罗网络在位置精度上提高了 0.006cm,角度精度提高了 0.2 度。
全局特征:全局特征在位置精度上贡献了 0.57cm 的提升,角度精度上贡献了 3.31 度的提升。
视觉特征:视觉数据在位置精度上提高了 1.55cm,角度精度上提高了 51.19 度,表明物体方向的推断依赖于视觉传感器的颜色特征。
与现有技术的比较:将基于视觉的最先进 6D 位姿估计算法 PoseCNN 在本文数据集上进行训练,结果显示其位置估计性能显著下降,角度误差比本文方法增加了 4.78 度,表明本文数据集对物姿估计具有挑战性。
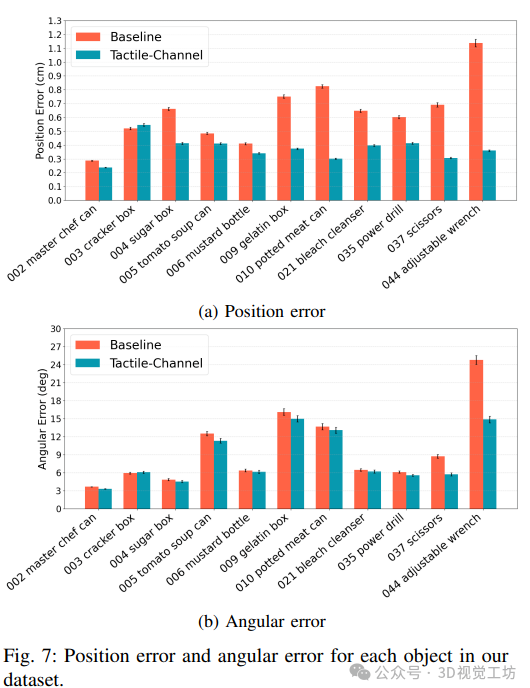
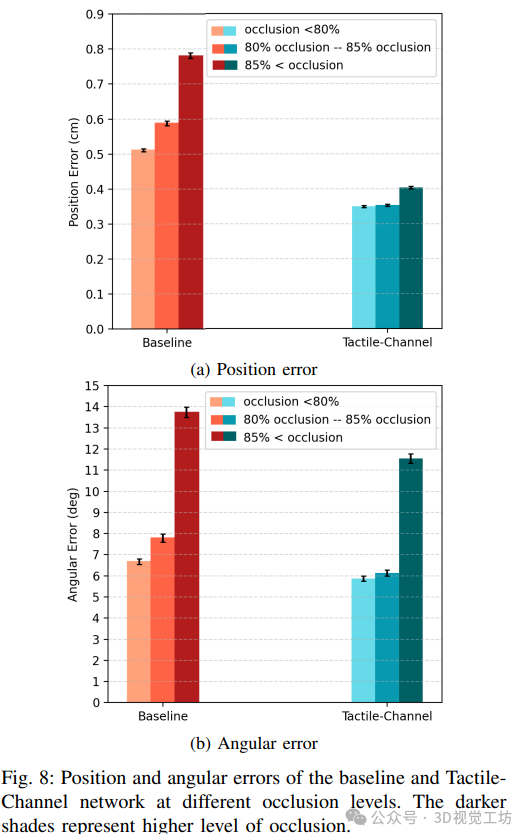

7. 总结 & 未来工作
总结
我们提出了一种新颖的方法来解决手持物体姿态估计问题。手持物体姿态估计的一个挑战是如何补偿物体大部分被遮挡部分的几何信息。在提出的方法中,我们利用了机器人手指上的触觉传感数据,这些手指会遮挡物体。我们提出了一种与传感器无关的表示方法,其中触觉数据由手指 - 物体接触表面点云表示。我们引入了一种视觉触觉网络架构,在该架构中,来自视觉和触觉传感器的数据以有意义的方式融合。为了有效地训练我们的模型,我们提出了一种合成数据收集程序,以生成适用于手持物体姿态估计的大规模视觉触觉数据集。
我们展示了将我们的方法与仅使用视觉数据的基线方法进行比较的实验结果。我们在合成数据上的结果表明,我们的网络在统计上显著优于仅使用视觉数据的基线方法,尤其是在严重遮挡的情况下。我们还展示了一项研究的结果,在该研究中,我们将触觉输入的数量在 4 到 240 之间变化。我们的结果表明,虽然估计的准确性有所下降,但即使触觉输入数量减少到 4,我们的方法仍然优于基线方法。此外,我们展示了将我们的网络部署在具有不同硬件设置的真实物理机器人上的定性结果。我们的定性结果表明,仅在合成数据上训练的网络可以成功迁移到现实世界设置中。
未来展望
我们的方法的一个局限性是,方向推断依赖于视觉传感器获取的物体颜色特征。虽然我们的方法在中度到重度遮挡情况下能保持性能,但在非常严重的遮挡下,性能会下降到与基线方法相当的水平。为了缓解这一局限性,未来可以采取多种方法。一种方法是使用长短期记忆网络等方法,利用时间连贯性来过滤错误的估计。另一个有趣的方向是利用抓取器的几何形状和手指的位置,帮助网络过滤掉物理上不合理的姿态估计。
我们数据集中的大多数物体至少在一个轴上是对称的。未来,我们希望扩展数据集,纳入 3D 打印的不对称物体,以评估我们的方法在这类物体上的有效性。我们还注意到我们的方法对环境遮挡具有鲁棒性。未来,我们希望进行一项研究,测试我们的方法在不同程度环境遮挡下的性能。