

成果巡礼
过去十多年里,AI 在图像识别、面部识别、姿态估计等领域飞速发展。从自动驾驶、智能监控,到社交媒体滤镜、增强现实,视觉 AI 几乎无处不在。但与此同时,人们也越来越意识到一个问题:许多视觉 AI 模型,在多样性等方面缺乏深度,并且持续传递着偏见。
这些数据集损害了 AI 模型的公平性和准确性,并剥夺了利益相关者的权益。为此,索尼 AI 推出了公平的以人为本的图像基准 FHIBE,可作为许多以人为本的计算机视觉任务的公平性评估数据集,包括姿态估计、人员分割、人脸检测和验证,以及视觉问答。
相关研究内容,以「Fair human-centric image dataset for ethical AI benchmarking」为题,发布在《Nature》。 论文链接:https://www.nature.com/articles/s41586-025-09716-2
论文链接:https://www.nature.com/articles/s41586-025-09716-2
设计中的考量
传统多数视觉数据集来源于网络爬虫和未经授权的图像采集,往往缺乏:
数据主体同意与授权
人口与地理多样性
详尽结构化标签(肤色、发色、年龄、性别、自我认同等)
环境 / 拍摄条件 / 器材 /背景 /姿态 /遮挡 等现实复杂因素
这些不足不仅违背伦理,更使得模型对多数人群的表现不确定、容易引入偏见。更糟的是,在某些任务(如视觉问答、姿态估计、人像分割)上,缺乏适合的大规模公开基准集,导致开发者无法系统检测或纠正偏差。
故而,评估模型和减轻偏见对于伦理人工智能的发展至关重要。
索尼 AI 所提出的 FHIBE 数据集来自于 1,711 名主要受试者,包含 10,318 张共计 1,981 个独特个体的图像,每个主要主题平均有六张图像。这个数据集还具备自我报告的姿态和互动标注,囊括了各种身体、头部、互动姿态,与丰富的人体外观特征。 图示:FHIBE 中所有图像都提供了关于图像主体、工具和环境的标注。
图示:FHIBE 中所有图像都提供了关于图像主体、工具和环境的标注。
此外,FHIBE 包含两个衍生人脸数据集,这两个数据集也同样包含所有标注。
与现有数据集相比,FHIBE 作为唯一一个为人工智能评估和偏差缓解而收集的数据集,具有坚实的同意基础;相比其他基于同意的数据集,在诊断人工智能中的偏见方面具有更大的实用性。
此外,FHIBE 在同意驱动的数据集中因其详细且自我报告的人口统计标签而脱颖而出,这些标签能够支持在人口统计属性复杂交叉点的模型性能研究。
评估与发现
FHIBE 的多样化和全面的标注在公平性评估中提供了广度和深度,能够评估模型在一系列人口统计属性及其交叉点上的表现。
通过在对多个流行模型和不同任务(比如姿态估计、人脸检测等)进行系统测试,研究团队很快发现了一些问题,基于多个敏感属性(包括代词、年龄、血统和肤色)的交叉群体在表现上存在最大差异。
在年龄上,年轻人,尤其是浅肤色的会更频繁地出现在表现较好的群体中;老年人,尤其是肤色较深的,则与其相反。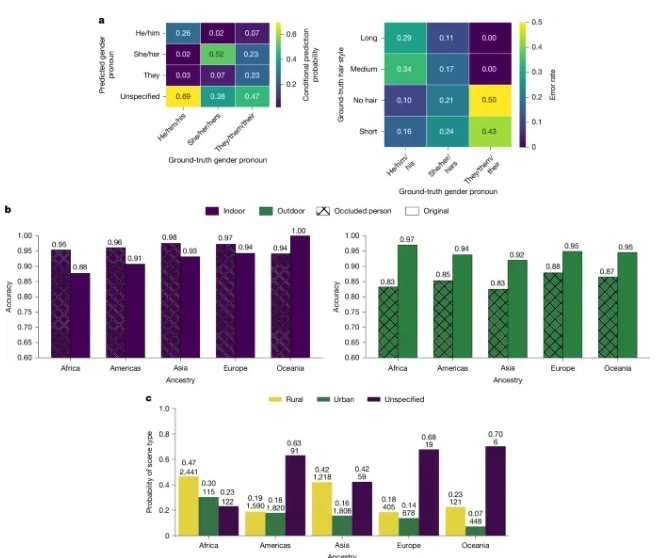 图示:CLIP 在 FHIBE 上的预测偏见。
图示:CLIP 在 FHIBE 上的预测偏见。
对于一些模型甚至存在意外偏差来源,如:面部识别模型对“光线较差 + 拍摄距离远 + 面部遮挡 + 特定发型 /面部毛发”的组合极为敏感,这些情况在传统数据库中很少遇到,也因此从未被系统测试过。
此外,在评估使用不同观测数据集的模型时,常常会出现相互冲突的偏倚趋势。除了上述的肤色、发色影响之外,动作姿态的不同也会导致偏差出现。这些发现强调了解决模型错误相关来源的重要性,并有助于指导开发者优化模型。
而对于两个受试模型 CLIP 与 BLIP-2,前者更倾向于默认主体为男性,对不合刻板印象的场景存在更多偏见;后者则更倾向于默认为女性,且对负面提示会更具有性别与肤色偏见。利用 FHIBE 会更轻易地发现这些未被记录的偏差,这些观察凸显了这些模型中持续存在的偏见,并强调了采取偏见缓解策略的必要性。
让 AI 看清世界
FHIBE 标志着更负责任地让 AI 发展的一个转折点,其中的一项关键贡献就是落实了许多仅在倡议中被反复呼吁的原则,为未来的伦理数据收集工作铺平了道路。
创建一个以人为本的数据集本身就具有挑战性,这其中还需要考虑到数据贡献者与实验参与者所需要付出的成本。总体来看,考虑到训练最先进AI模型所需的大量数据,协商、多元且合理报酬的数据收集成本依然很高。
但这不是放弃工作的原因。实验团队希望凭借 FHIBE 整合全面且经共识来源的图像和标注,为 AI 系统建立负责任的数据集新标准。通过实施负责任的数据实践,并使计算机视觉社区能够测试其模型的偏见,FHIBE 可以帮助推动更具包容性和可信赖的 AI 系统的发展。